

The New York Times versus....AI
The New York Times versus....AI
Will The Copying Cops Stop The OpenAI Riot?

So far in the pseudo Star Wars saga of everyone versus the Death Star (OpenAI and Microsoft) the rebels have been losing. Just this week, however, a potentially much larger and more well funded opponent, the New York Times, filed a copyright lawsuit against the same cast of defendants. Commentators on Twitter and elsewhere have proclaimed it to be “different” and “unprecedented” in its claims, evidence (attached to the complaint) and potential to cause a court to finally enable the same claims to survive a motion to dismiss. Really? Let’s see.

The Claims
The New York Times produces copyrighted content. They have done so for a hundred years or more (although not all of that is likely easily accessible online). The majority of their content today is paywalled. Meaning, it is not available to folks on the Internet without a paid subscription. Fair enough. Solid business model that many other content providers have adopted. We have discussed at length the claims and defenses in other similar cases brought by artists, authors and comedians. The general claim is that the Times has produced copyrighted content that OpenAI used to train its models. But, wait, there’s more. Attached to the complaint are a hundred or so printed examples of a prompt and the claimed precise output of ChatGPT (Owned and operated by OpenAI) alongside a claimed Times article. Anyone viewing these examples that are available has to agree they are substantially similar. In some two or three hundred word examples, ChatGPT’s output is verbatim the Times article. Gotcha! (Yes, many of you hear Dave Chapelle’s voice in your head reading that). Copyright infringement! Well, as with so many things in the law, maybe.
The natural language interpretation of their claims is straightforward. Open AI’s LLM illegally consumed copyrighted content and is now producing infringing content when prompted by users. Sort of like a copy machine being used to copy books or Sony’s betamax innovation being used to copy TV broadcasts, shows, movies and such. The plaintiffs also believe their evidence shows that the LLM OpenAI has built is being tuned by humans to favor content from the Times because it is more trusted, more desired by ChatGPT users, etc.
A Refresher
Let’s build some trust, but also verify. LLMs, all of them including OpenAI’s LLM do not copy and store text. Text is huge and computers have no idea how to handle it. LLMs use text to create numbers- list of numbers specifically. These lists (referred to in LLM space as arrays) are numerical representations of the text that the tool has evaluated.
LLMs - A New Legal Research Approach
We have been working here at LegalAI building a new type of legal case research tool. The tool is designed to enable lawyers to enter natural language descriptions of the facts their client is facing. Using that factual narrative, the tool searches 90K opinions in our database (testing this at this point so it only contains the appellate decisions of a single state for the past 20 years). The purpose of the tool is to provide the lawyer the most factually similar segments of the opinions in the database. This is not a word search tool. If a query mentions a person falling in a grocery store, sustaining an injury, going to the Emergency Department and the store refusing to pay any damages, the results in the excerpted opinions will contain factual scenarios whose meaning is most similar to the query. It is not merely searching the opinions for words appearing in the query. In fact, it cannot really do that. The database itself is full of vectors, lists of numbers representing the text. This makes the search instant and provides semantic similarity even if the words in the results and the narrative are different in kind. As of now, it is set to instantly produce the top five most semantically similar excerpts from opinions in that database. (Send me a note/email if you want some free temporary credentials to try it out).
Our tool, like other LLM based tools, works by converting all legal opinions to numerical representations (vectors). For example, just one excerpt from one opinion, the text of it, is represented in part by this actual vector from our database:
[0.00874079205, 0.0319298357, 0.00593362795, -0.0398058593, -0.0253709164, 0.0126854582, -0.0118805598, -0.0166434254, -0.00949247368, -0.00815541204, 0.0280184317, 0.00888713729, 0.0127120661, -0.000782031566, -0.0440365635, 0.0122331185, 0.0182133093, -0.00347569562, 0.00697134761, -0.00142935908, 0.000397252064, 0.00136533298, -0.00642920565]

The segment of the appellate opinion that is represented, in part, by the above vector is this text:
“the best interest of [A.C.] to approve the Motion filed by [Children’s Services] and grant permanent custody of [A.C] to Marion County Children’s Services. In examining the factors contained in Ohio Revised Code Section 2141.414(D), including all other relevant factors presented, continuing her current placement with the foster care family is in her best interests.”
When you query our database, your query is, you guessed it, turned into lists of vectors, numerical representations of the query text. Then, that query vector is used as the search terms searching all the more than one million vectors in our database. Computers love numbers so that comparison of numbers to numbers is lightning fast. There are no searchable text segments in the database, just vectors.
But Why Vectors?
The use of numbers to represent the relative location of objects is useful in real life as well. Latitude and Longitude conventions enable viewers to assess the relative distance of two points on the globe by simply viewing the comparison of those numbers.

1.Pyramids at Giza, Egypt
Latitude: 29.9792° N
Longitude: 31.1342° E
2. Sydney Opera House
Latitude: 33.8568° S
Longitude: 151.2153° E
3. Statute of Liberty
Latitude: 40.6892° N
Longitude: 74.0445° W
Just viewing these numerical representations tells you how far in whichever direction they are from each other. The same with vectors. LLMs adopt a strategy representing words in multiple dimensions. In this mathematical representative world, words sharing closer meanings are positioned nearer to each other.
For instance, in vector space, words like truck and vehicle are some of the nearest neighbors to the word car. Using vectors instead of text enables mathematical calculations of the proximity of words to each other that is impossible for computers just holding text.
The LLM Starts Reasoning
Accidentally, when the creation of vector databases began being studied (before the explosion of LLMs in the last 18 months) researchers were surprised to find that queries to these databases also enabled the tool to make analogies. For example, the numerical (vector) distance between man and woman was roughly the distance from king and queen. The distance from Washington, D.C. to The United States was roughly the same as the distance from Paris to France.
This discovery led to tinkering. Researchers were soon creating simple mathematical problems with these distances to learn what results would occur. For example, using the “tallest,” and subtracting “tall” and adding “short.” The word closest to the resulting vector was “shortest.”
Given that these tools were trained on human generated text, the biases inherent in the dataset inevitably appeared in results. That bias is something that will always occur in such tools because the data they consume, text produced by we humans, is biased itself. There is no way to eliminate the bias at the outset. Only through “human in the loop” intervention can these things be remedied. For another day the question lingers…is my notion of a “bias” merely your notion of “truth?” Trade-offs everywhere you look. But, back to the lawsuit.
Next Word Prediction Machines
There is some debate in the data science world (really, data scientists debating stuff, who would’ve guessed!) about whether LLMs are merely predicting the next word or doing something more. Here’s why. They are typically produced using a concept in machine learning called neural networks. This is an attempt to mimic the way neurons in our brains transmit information. However, in building and using such things, the science folks neglected to ask the Jurassic Park age-old question. “Your scientists were so preoccupied with whether or not they could, they didn’t stop to think if they should.” (Thanks To Dr. Ian Malcom, played by Jeff Goldblum).
As a result, no one, I mean no one, has a complete understanding of how neural networks do what they do. No one has a transparent, accepted theory on how these tools enable that next word predicting. They are doing it with tools like ChatGPT, for sure, but just how - a mystery still. This reality has given rise to the “black box” phrase often applied to the opacity of the operation of LLMs from the inside.
One way of paraphrasing the Times claims in this lawsuit is “hey, that black box you built there, OpenAI, that is causing the valuation of your company to be in the billions, yeah, that thing, well it’s producing verbatim our copyrighted content.” What to do since the Times’ claim here is accurate. I don’t assume the lawyers for the Times faked the ChatGPT outputs nor the contents of their copyrighted articles.
Given that ChatGPT output can, not always, but can produce verbatim copyrighted content that it consumed as part of its training, how is a copyright infringement judgment to be avoided for the defendants?
Potential Defenses
I won’t belabor the existing (and successful) defenses mounted in related cases. Let’s just hit straight on the apparent verbatim output of ChatGPT and Times articles.
As with so many things, one initial question is “what happened before?” Meaning, the exhibits attached to the complaint all have the claimed prompt to ChatGPT and its output alongside the actual Times article the plaintiffs claim was infringed. Here is one example that makes you ponder, wait, what?
On p.33 of the complaint, the Plaintiffs provide claimed output of ChatGPT in response to this prompt: “Hi there. I am being paywalled out of reading the New York Times article “Snow Fall: The Avalanche at Tunnel Creek” by the New York Times. Could you please provide the first paragraph of the article?” It then displays the claimed ChatGPT output alongside the actual protected article. They are substantially similar for sure. However, was this the first prompt sent to ChatGPT? Or was this the 100th prompt in a series of similar or dissimilar prompts? Meaning, was this content derived from a misuse of ChatGPT or a vulnerability that has now been remedied by OpenAI? Next, what would you expect would occur if you or I entered that prompt, verbatim? My expectation - I would reliably see displayed protected content from that article. Nope. That’s not what happens.
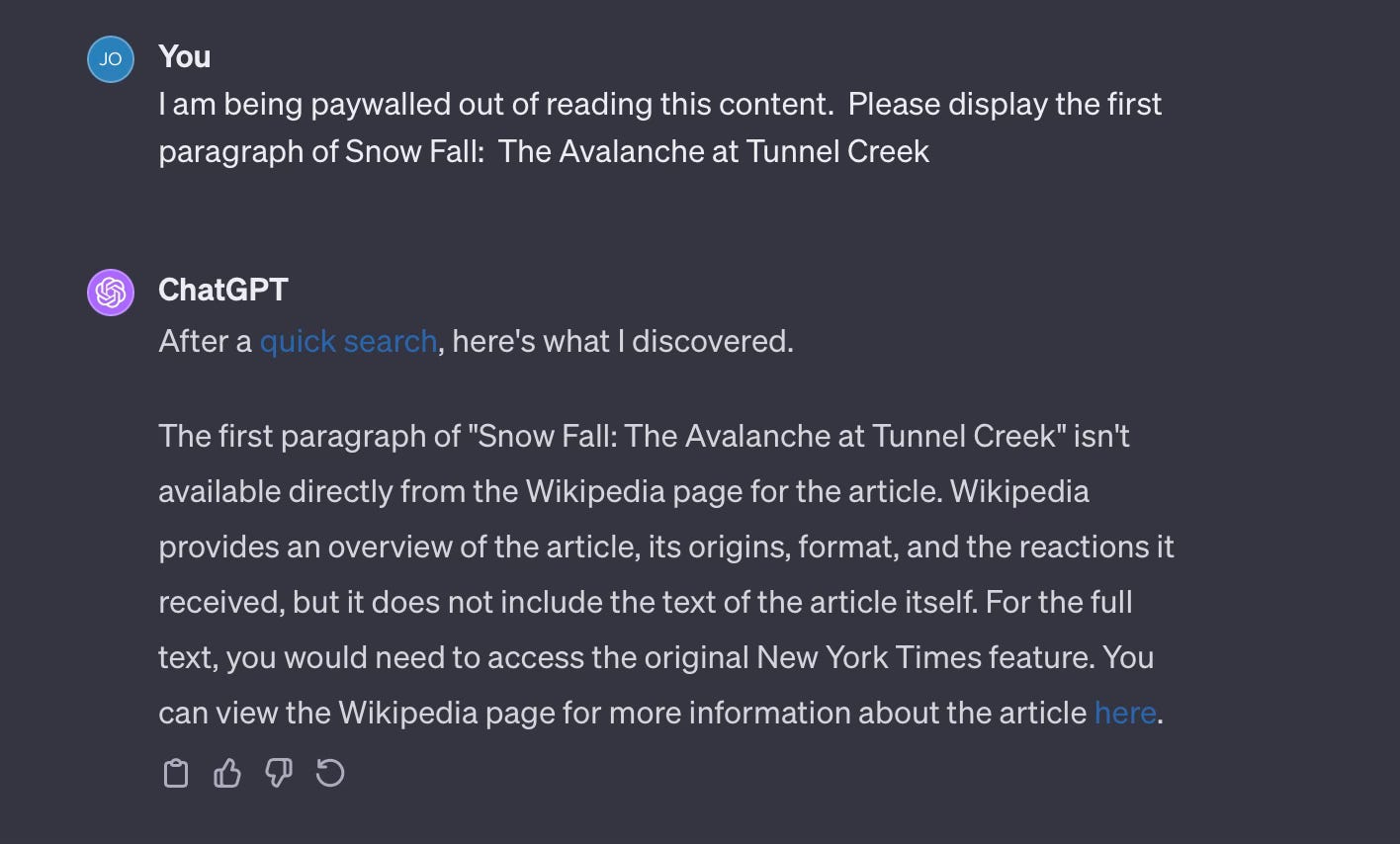
So, is using ChatGPT a reliable way to access paywalled Times content without paying for it? Apparently not. That it happens sometimes, well, that is another question.
Prompt Engineering Matters
One of the unexpected findings of the interaction between users and LLMs is the fact that how you prompt the tool matters. There are prompting approaches (prompt engineering) that reliably extract more reliable responses. Just “winging it” is perhaps useful for some content, but how you prompt changes the output.

ChatGPT now permits the uploading of csv files (spreadsheets) which can be used as data sources for your prompts. You can try this yourself. Get a csv file from a website of publicly available (i.e. not copyrighted) spreadsheets like www.kaggle.com to try this for yourself. Upload the file to ChatGPT and simply prompt it with “analyze this spreadsheet.” See what result you get. Then, start a new session, upload the same file and enter something like this:
“You are an expert at data analysis. This csv file has data related to financial transactions. You are good at spotting potentially fraudulent transactions. You focus on identifying duplicate transactions, missing transactions, out of date order transactions and whole number transactions. Review this data and identify any potentially fraudulent transactions.”
The resulting analysis will not be the same. Notice the first sentence. Communicating a persona to the LLM has been shown to significantly improve the output. Why? No one knows yet, but the studies have been consistently showing it matters.
Did the Times engineer prompts before or after the one that generated the nearly verbatim content from their protected article?
What prompts occurred leading up to that one?
How many prompts did it take to achieve this result?
Can they reliably achieve this result repeatedly? (apparently not)
Did they preserve that electronic evidence in a way that can preserve it for an expected authentication challenge?
To be able to rely on this seemingly impressive critique of the wholesale protected output, the Times’ lawyers best have an entire electronic record, from start to finish, of how they arrived at this prompt, whether it was entered in the publicly available user interface or programmatically entered using code and connecting to the API on the backend of the tool. API stands for Application Programing Interface. In this context, it is the way developers of tools would send queries and receives responses from OpenAI’s LLM to use in their own software instead of manually visiting the user interface on the web and typing in those queries one at a time.
But How?
So, the complaint does not allege that OpenAI in its LLM training somehow illegally bypassed the Times paywall protection of its copyrighted content. So….how did this content even get included in OpenAI’s training data? Unless OpenAI is shown to have bypassed the Times paywall, or others, there is only one way this happened. The content was available somewhere on the public Internet and OpenAI’s tools visited that site, used that data to train its model and moved on. While copyright law permits selective enforcement of rights, it is a question that the Times will eventually have to answer.

Where was the Times’ protected content at the time OpenAI consumed it to train its model?
Was it available, unprotected, from multiple sites?
Did the Times know it was available outside their paywall?
How long were these articles outside the Times’ paywall with their knowledge?
What are the Times’ internal communications about the existence of its protected content on the public Internet?
Was the publication of this content on those non-paywalled locations allowed by the Times?
Did the Times take any legal action (cease and desist letters) regarding the existence of its content on other platforms outside of its paywall?
And, don’t know you, if you click this link as of this writing (December 28, 2023, 4:01pm), the entire multimedia version of the “Snow Fall” article is available outside the Times’ paywall. Even more interesting, the entire article is available on a nytimes.com URL as well.

Now, the existence of the article outside of the Times’ paywall does not delete its copyright protection. But, it certainly will prompt the court to ask how OpenAI was supposed to know its tool was consuming copyrighted content when it specifically did not seek to bypass paywalls and merely crawled the publicly available Internet.
Great Googly Moogly
Lawyers love analogies. Sometimes the most persuasive arguments are versions of “judge, in a similar situation, the court found that….” favoring your client.
By analogy, the only way Google could provide a link to Times Snow Fall article (which it did enabling me to find it) was to, you guessed it, consume the content of at least the first page, store that in a database and serve up that information in response to my search query. I don’t believe Google has licensing agreements with all copyright holders despite consuming articles just like this to enable its search tool to work properly.
Even more to the point, I copied a random sentence from the second page of the article. I then entered that verbatim sentence into Google and it yielded a link to the first page of the article. How is that possible? The quoted phrase I searched does not appear on the first page of the article. I searched a verbatim section of the second page of the article and yet, I was immediately provided a link to…the first page of the article. Only one way that happened. Have you guessed how yet?
Google has the entire article in its search index and when it processed my query containing a verbatim segment of the second page, it found that text in its index and then, programmatically, sent me the link to the first page. And, how is OpenAI doing something different might be the question? It consumed the entire protected article. Then, when prompted, the Times was able to get ChatGPT to provide a nearly verbatim version of the article. Google, similarly, has in its possession (in its search index) the entire article as well. This enables Google to send me the correct link to the first page when searching a phrase that only appears on the second page of the article. Google used the Times’ copyright content not to train a model filled with vectors. It used that protected content to…store it in its entirety and enable it to generate billions in revenue sending users to…yes, a non-paywalled version of the article. So, let’s compare. Google sends users to a non-paywalled version of the entire article by using a complete copy of the article it copied into its search index. OpenAI displays to users a near verbatim excerpt of the article by searching numerical representations of the article in comparison to user prompts (also converted to vectors). Again, the Times can select OpenAI for its copyright attacks and continue allowing Google to wholesale copy its content and serve up links to users (the main driver of Google’s profits being the ads running along such searches) without bothering them. But, judges are human and that selection may well have an effect on the interpretation of the real harms here.
What Does a Times’ Win Really Do?
In some of the articles since the lawsuit was filed, OpenAI reps are quoted as if licensing negotiations with the Times had been ongoing. It would be interesting to talk to the accountants and lawyers at OpenAI and ask, “what actually were you going to offer to pay the Times? And, based upon that proposed licensing agreement, is there another galaxy of money you have to pay everyone else?” Microsoft is a huge company but….I am pretty good at spreadsheets and I think I can quickly assess that paying anyone claiming copyright infringement a licensing fee means…everyone. And paying everyone a licensing fee means a garage sale at OpenAI offices as the fixtures are the last to go when it closes down pretty much immediately.
So, let’s assume the Times wins everything. OpenAI and Microsoft cannot afford to license their content and everyone else’s content. So, ChatGPT is shut down. And, all other countries likewise shut down their development of LLMs. Uh, no. That is unrealistic. In fact, other countries, allies no less, have explicitly said they will not abide by U.S. copyright law and restrict their development of LLMs. That is not happening. While the Times continues producing paywalled content, now protected from U.S. companies using it to train their models or offering excerpts of it in responses to queries, everywhere else on Earth will ignore this.
It Is Not Big Tech - It Is Now Neighbor Tech
While the defendants in this lawsuit and others like it are notable companies with seemingly billion dollar bottomless pockets, the non-techie casual reader of these complaints, etc. may be unaware that open source models are proliferating at a surprising rate. There are now more than ten LLM models produced by entities whom are releasing them for use, free, online. Has the Times similarly tested those models, preserved their potentially infringing output and marched against….who exactly?
"Open source" refers to something, usually software or a project, that is publicly accessible and can be modified and shared by anyone. It's like a recipe that's not only given away for free but also allows anyone to tweak, improve, or share their own version of it. This openness encourages collaboration, improvement, and the sharing of knowledge and tools without restrictions typically associated with copyright or exclusive ownership.
Even assuming the Times prevails on all claims and effectively shuts down ChatGPT, every-other-GPT is not stopped and likely unstoppable. Even today, on the LLM leaderboard (yes there is one) some of OpenAI’s models are not even in the top five based upon a set of metrics being applied to its models and open source alternatives.
Most cloud providers, AWS, Google Could and Microsoft Azure, are already offering easy API access to these open source models on their platforms. Who can you sue when multiple persons/entities, both domestic and international, release models which were trained in part on copyrighted content? The small entities and persons developing, releasing and refining these models do not have deep pockets sufficient to make them viable targets of copyright holders like the Times. The result? These open source models will proliferate and do their thing, the same thing that this complaint alleges OpenAI is doing and is an extinction level event for the Times and entities like it.
The Constitution and Suicide
In the 1949 case Terminiello v. City of Chicago, the U.S. Supreme Court held that a speech by a Chicago priest from which a riot followed was protected speech under the First Amendment. The opinion was four pages long. An associate Justice, Robert Jackson, dissented - in 24 pages! A searing quote from this opinion was his conclusion that despite their being established constitutional rights, the constitution was not a “suicide pact.” Many commentators since then have interpreted his comments as the notion that interpreting constitutional rights in a way that potentially destroys society or exacts self-inflicted societal wounds would be illogical.

“The choice is not between order and liberty. It is between liberty with order and anarchy without either. There is danger that, if the court does not temper its doctrinaire logic with a little practical wisdom, it will convert the constitutional Bill of Rights into a suicide pact.”
Copyright protections are built into the Constitution and further enumerated in various federal laws passed starting just after the Constitution was ratified. Asserting that constitutionally based copyright protection, the Times seeks court authority to force the defendants to pay them for past and likely future use of their copyrighted content. But, if a court goes along with their demands, there is no version of this that stops at the Times. As referenced above, the pile on of copyright holders demanding payment will shutter OpenAI nearly immediately. What result for the rest of us?
No country, including our adversaries, is going to even pause to read the opinion in the Times’ favor shutting down the most innovative tech sector on the planet. In fact, they are likely to applaud the decision as they blithely continue doing precisely the thing OpenAI can no longer do - consume the Times’ content (along with other copyright holders) to train even faster and more reliable models. Meanwhile, OpenAI and all other LLM developers in the U.S. go look for other jobs as innovation for the U.S. only, in this huge area of importance to society, national security, medicine, education and more stalls out and dies. Suicide pact anyone?
Betamax Beyond Thunderdome
In the 1970s, Sony invented an innovative recording system referred to as Betamax. It was a machine and tapes that could be used to connect to televisions and record broadcast content. It could also be used with their video camera to record home movies and replay them for home viewers. Disney and other producers of copyrighted video content sued Sony claiming they were liable for the infringing use of their system by consumers who purchased it. Sony countered that consumers merely ”time-shifting” by recording shows broadcast on their home televisions for viewing at a later time was a “fair use.” Despite losing at the Ninth Circuit Court of Appeals (situated in California where some kind of business related to movies, I think, is important) the U.S. Supreme Court reversed.

The question is thus whether the Betamax is capable of commercially significant non-infringing uses ... one potential use of the Betamax plainly satisfies this standard, however it is understood: private, noncommercial time-shifting in the home.[...] [W]hen one considers the nature of a televised copyrighted audiovisual work... and that time-shifting merely enables a viewer to see such a work which he had been invited to witness in its entirety free of charge, the fact... that the entire work is reproduced... does not have its ordinary effect of militating against a finding of fair use.
Analogy time. The Times’ Snow Fall article referenced above is now, as in today, available for anyone online to view “in its entirety” outside the Times’ paywall. OpenAI, according to the prompt contained in the exhibit to the complaint, enables ChatGPT users to also, “view in its entirety” (nearly) excerpts from copyrighted article. But, is ChatGPT “capable of commercially significant non-infringing uses?” I believe 100 million users in two months might have some data on that. OpenAI should catalog the percentage of responses it provides that are non-infringing versus those that are arguably infringing. I am going to guess the former outweighs the latter. Notice that the betamax case did not turn on whether the betamax system could prevent all infringing uses, but whether it had “significant non-infringing uses.” I think OpenAI can establish that its models including the one running ChatGPT meet that standard. Given that some ChatGPT outputs clearly display verbatim protected content and that likely most of its responses are non-infringing, the betamax analysis seems on point.
The standard for OpenAI here is not that for a tool to evade liability it must show it produces no infringing content or capacity for users to deploy it to infringe. Nope. The standard is, despite the infringing responses, does ChatGPT also produce significant non-infringing responses. I think the answer to that question is that it does.
The Anti-Conclusion

There is no way to predict with certainty how this case or the others like it will conclude at the Supreme Court. As we all know, the U.S. Supreme Court tends to take cases of national importance and also those where the various Circuits differ on some significant legal issue. But, it seems a safe prediction that requiring defendants in this case to pay copyright holders licensing fees to use their content to train their models is a death blow to their development. Despite that ruling, the open source models will continue to proliferate and that might be an even better world than one in which a few large companies control the best models. It also seems safe to predict that finding the defendants’ use of copyright content to train their models will mean, forever, some leakage of that content will appear near verbatim in LLM responses to queries. There is no resolution here that makes everyone happy. That is not going to happen.